ご無沙汰しております!QAZです!
更新を怠っていました!
この間に2つも資格に落ちていたりするのですが
それはまたあとでお話するとして。。。
今日は、ふとTwitterのTLを見てて
思わず反応してしまったtweetがありました。
この投稿に、私も反応していますが
伝えきれなかった、データベースエンジニアの思いがありますので
そちらについて、記事にしたいと思います。
目次
結論:技術の進歩、DB設計の新しい考え方の登場に伴い、ログインID=メアドが可能となった
私の持論はこちらになります。
逆を言うと、昔のデータベースエンジニアの思考から変わってない方は
今だにログインID≠メアドだと思います。
この理由について、お話していきたいと思います。
【前提】私がデータベースエンジニアになった頃の環境
まずは、私がデータベースエンジニアになったのは、2002年でした。
当時の環境は以下の通りです。
①サーバのスペックが今と比べて劣っていた。
これはいろいろありまして、CPUもそうですが
メモリ、ハードディスクの容量も今と比べてそうとう小さい頃でした。
今では信じられないかと思いますが
当時8MBのUSBメモリを3,000円くらいで買って使っていました。
それくらい、容量は今と比べるとホントに小さかったです。
②データベースの物理設計が、レスポンスに影響を与えまくっていた
どういうことかというと
主にインデックスであったり、セグメントのサイズ、ブロック内の空き比率(PICTFREE等)が
結構シビアに影響していたのを覚えています。
③データベースのオブジェクトの種類がそんなに多くなかった
昔のデータベースオブジェクトとしては、テーブルとインデックスの2種類が主流で
今では当たり前になっているSEQUENCEであったり、制約(単語忘れた)は
DBMSによっては無かったり、あっても使わなかったりしました。
【昔のDB設計の考え方】洗い出した項目の中からプライマリキー(PK)を決定する
結構この考え方が、通常のデータベース設計の基本になっていると思います。
例えば、下記のような画面があったとします。

この画面から項目を洗い出して、例えば会員基本情報と会員ログイン情報という2つのテーブルで管理すると
下記になります。
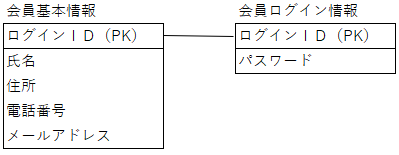
この時、前述しましたが、まだSEQUENCEがメジャーではなかったので
ランダムな値を内部的に持たせてPKにするという考えが主流ではなく
画面から項目を洗い出した結果、ログインIDがPKとして選ばれます。
ここで、メールアドレスをPKにしない理由が2つあります。
メールアドレスをログインIDにしなかった理由①:メールアドレスは変更する可能性がある
メールアドレスについては、例えば会員が使用しているプロバイダが変わったり
会社メールであれば、退職したり企業再編等でメアドが変わることがありました。
※当時はGmailがそれほど主流ではなかった。
そのため、メールアドレスをPKとしてしまうと
・変更するとPKを変えなくてはならず、関連するテーブル全てのPKを更新する必要がある(上記の例だと2つのテーブルの更新が必要)
・PKを更新すると、インデックスの格納効率が悪くなり、結果レスポンス悪化に繋がる
・(PKを含めて)インデックスを更新するとインデックスの再編が行われ、無効領域が発生する
というリスクが考えられ、このリスクを回避すべく、PKの項目に採用されていませんでした。
私がやりとりしてきたプログラマーの方は、インデックスの格納効率や無効領域について
それほど重要視していませんでした。
ただ、インフラも携わった私としては、このインデックスと無効領域はとても慎重になっていました。
昔のテーブルは、容量の上限値というものを指定していることが多く
インデックスの再編→無効領域の発生を繰り返すことで
テーブル容量の上限値に達してしまい、その結果DB更新エラーが発生して
システムが止まったりしました。
インデックスは、本でいうところの目次のようなものです。

この「い」を「か」に更新した場合にどうなるかというと
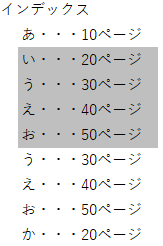
という再編が行われ、グレーの部分はデータが削除されるだけでなく
無効領域となります。
「無効領域」とは何だ?という話ですが
データのUPDATEやDELETE、インデックスの再編の際に
以前データが格納されていた領域が以後使用できなくなる、という領域です。
上記の例でいうと、グレーの部分が無効領域となり
以後、データベースで切り捨ての操作を行わない限りは
再利用できない領域となります。
この領域が大量に発生すると、いくらハードディスクの容量があっても足りなくなるため
PKを含めたインデックス項目の更新はご法度という認識が一般的です。
メールアドレスをログインIDにしなかった理由②:メールアドレスの文字列が長すぎる
これ、みなさん「何のこっちゃ?」と思うかもしれませんが
当時の状況でもお伝えした「サーバのハードディスクの容量」にも関係してくるのです。
例えば、ログインID8桁固定と、ログインID64桁可変だと
どう考えてもログインID64桁可変のほうが、容量を多く使用するのはわかるかと思います。
64バイトの可変項目の平均が30バイトで
会員数100万人、テーブル数が50テーブル、インデックスがテーブル数の1.5倍だとすると
(30バイトー8バイト)×1,000,000人×50テーブル×75インデックス = 83.82GB
PKだけでこの容量は、当時は正直厳しい。。。
(今はこれくらい平気だと思いますが)
ちなみに余談ですが
SELECT文の、SELECT句の項目の指定の仕方で速度が変わってきます。
早い順にいうと
①SELECT 固定長項目(,固定長項目・・・) FROM テーブルA;
②SELECT 可変長項目(,可変長項目・・・) FROM テーブルA;
③SELECT * FROM テーブルA;
です。
よくレスポンス重視のシステムで、いろんな項目を1つの固定長項目にして
SELECTしているケースがあるかと思います。
これは、固定長項目だと文字の長さを気にすることなくデータブロックを参照できるから早いのです。
可変長項目は、長さを調べながらになるので時間がちょっとかかり
SELECT * は、ディクショナリ表から対象のテーブルに存在する項目の情報を取ってくるので遅くなります。
データベースエンジニアとしては、こういう点が気になって
メールアドレスをログインIDにすることを避けていました。
【新しいDB設計】SEQUENCEオブジェクトが主流になり、画面に出ない値をPKにするようになった
私はSEQUENCEオブジェクトの登場によって
内部的に数値項目を管理することが可能となり
DB設計に影響を与えたと考えています。
とにかく、採番が楽になりました。
そして、採番した内部的に数値項目を管理して、その項目を各テーブルのPKとすることで
今まで問題になってきた
・インデックスの再編
・無効領域の発生
・データ容量
といったことが解決できるようになりました。
※数値項目の場合、文字列項目と比べて容量が約2分の1になる
新しいDB設計だと、こんな感じになります。
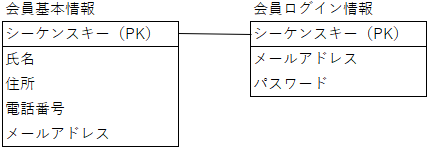
あとは、メールアドレスをログインIDにする場合
項目「メールアドレス」を、PKではない、普通のインデックスとして定義することが通常です。
理由としては、レスポンスの向上です。
その場合、やはりインデックスの再編や無効領域の問題が生じてきてしまうのですが
今のご時世、ハードディスクの容量が以前と比べて格段に増加しているので
あまり問題になることが少なくなってきました。
これは技術の進歩の部分に当てはまります。
あとは、単純にDBMSの性能の向上もあります。
これも「技術の進歩」ですね。
今では、テーブルのサイズ、空き容量比率といったDB物理設計をしなくても
レスポンスに悪影響を与えることなく使用できるようになりました。
【最後に】それでもメールアドレスをログインIDに出来ないケース
技術が進歩して、DB設計の考え方も変わったとしても
それでもメールアドレスをログインIDに出来ないケースがあります。
それは、「会社単位で使用するシステムの場合」です。
会社によっては、必ずしも社員にメアドを発行しているとも限らないので
その場合、メアドで登録ができないので
メアドではない、ユーザIDを登録することになります。
これは個人向けに公開されているサイトではあまり見られないことかと思います。
世の中、いろんなWebサイトがあるかと思います。
そんな中でも、裏ではこんな考えを持っている人がいるんだなぁ、と
心の片隅においていただけると幸いです。